
In this post, I’m going to demonstrate how to take backup of database without considering non clustered indexes.
Before describing how to eliminate index data from backups, it’s first important to
point out that a non clustered index contains simply a copy of the rows from its
associated table, sorted differently by the index’s keys to allow efficient searching
during processing of queries. Eliminating this redundant index data from routine
database backups does not limit the recoverability of the database data from its
backup; indexes can always be re-created later if necessary.
Before we create any tables and indexes, first we will create a database “TestBackup”
-- Create a testbackup to demonstrate the example CREATE DATABASE TestBackup;
This will create a database called “TestBackup” on a “Primary Group”. By default, SQL Server creates databases on a primary group unless you specifically mention.
Let’s see on what file-group the database is in
USE TestBackup; SELECT name, data_space_id, is_default FROM sys.filegroups;

Figure 1
By default, unless further filegroups are explicitly created, all the tables created within the database are stored in “Primary” Group.
Let’s continue by creating a simple table
CREATE TABLE dbo.Employee ( Employee_No INT NOT NULL primary key , Ename NVARCHAR(50) NOT NULL, Sal MONEY NOT NULL );
To verify that the preceding table is created within the PRIMARY filegroup, execute the
following command:
SELECT d.*
FROM sys.data_spaces d, sys.indexes i
WHERE i.object_id = OBJECT_ID('dbo.Employee')
AND d.data_space_id = i.data_space_id
AND i.index_id < 2;

Figure 2
Now, we will create non clustered index on Employee Table as below
CREATE NONCLUSTERED INDEX ncix_Employee ON dbo.Employee (Employee_No);
Verify on which file group the non clustered index created
SELECT I.NAME, I.INDEX_ID, I.TYPE_DESC, I.DATA_SPACE_ID
FROM SYS.DATA_SPACES D, SYS.INDEXES I
WHERE I.OBJECT_ID = OBJECT_ID('DBO.EMPLOYEE')
AND D.DATA_SPACE_ID = I.DATA_SPACE_ID
AND I.INDEX_ID > 1;

Figure 3
You can see that both table and index is on default Primary Group. See the Figure 2 and 3 for the column data_Space_id (=1). Next,we are going to add a new file group and secondary file for non clustered indexes as below and later move the non clustered index to newly added file group.
ALTER DATABASE TestBackup ADD FILEGROUP NCIX_FG;</pre> ALTER DATABASE TESTBACKUP ADD FILE ( NAME = N'TESTBACKUP_NCIX_FG1' , FILENAME = N'C:\RAM\TESTBACKUP_NCIX_FG1.NDF') TO FILEGROUP NCIX_FG;
To move the non clustered index from primary group to the dedicated new file group, we would need to create non clustered index with DROP_EXISTING command as below
CREATE NONCLUSTERED INDEX ncix_Employee ON dbo.Employee (Employee_No) WITH DROP_EXISTING ON NCIX_FG;
Note: DROP_EXISTING option causes the newly created index to be created as the replacement of the existing index, without needing to explicitly drop the existing
index .
With this the new non clustered index with the same name created in new file group.
Next, I will take Backing up only the PRIMARY file group and restore the PRIMARY file group.
BACKUP DATABASE TestBackup FILEGROUP = 'PRIMARY' TO DISK = 'C:\Ram\TestBackup_Primary.bak'
Restoring the PRIMARY file group backup
RESTORE DATABASE TestBackup_New FILEGROUP = 'PRIMARY' FROM DISK = 'C:\Ram\TestBackup_Primary.bak' WITH RECOVERY, MOVE N'TestBackup' TO N'C:\Ram\TestBackup.mdf', MOVE N'TestBackup_log' TO N'C:\Ram\TestBackup_log.ldf', NOUNLOAD, STATS = 5
Note: I have restored on the same instance with different name (TestBackup_New) and move the files to different folders. This will bring the database online and available for querying.

Figure 4
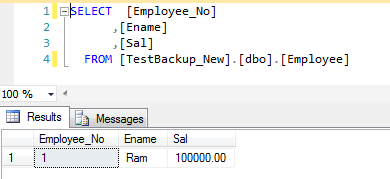
Figure 5
You cannot perform insert, update and delete commands because we have only restored the primary group, the underlying non clustered indexes associated with tables are offline. If you attempt to do, you would get the below error

Figure 6

Figure 7
Our main intention in this demonstration is to extract the data from the database without restoring non clustered indexes. This will be useful, if you are testing the data for analysis and you do not want to restore the non clustered indexes due to low disk space on the destination server.
Hope you enjoyed the post!
Happy Weekend!
Cheers
Ramasankar Molleti
LinkedIn: LinkedIn Profile
Twitter: Twitter

Nice article and great job compiling a bunch of useful tools into one post.
Enterprise accounting software